Architecture
Autobase Console
Autobase Console is the control plane of the platform. It provides a web-based interface and API for provisioning, operating, and monitoring production-ready PostgreSQL clusters across your own infrastructure, including physical servers, virtual machines, on-premises environments, and supported cloud providers.
This architecture allows Autobase to provide a DBaaS-like experience while keeping PostgreSQL clusters inside infrastructure controlled by the user. The Console acts as the single management entry point, while the actual database nodes remain independent Linux servers running PostgreSQL and the selected high-availability components.
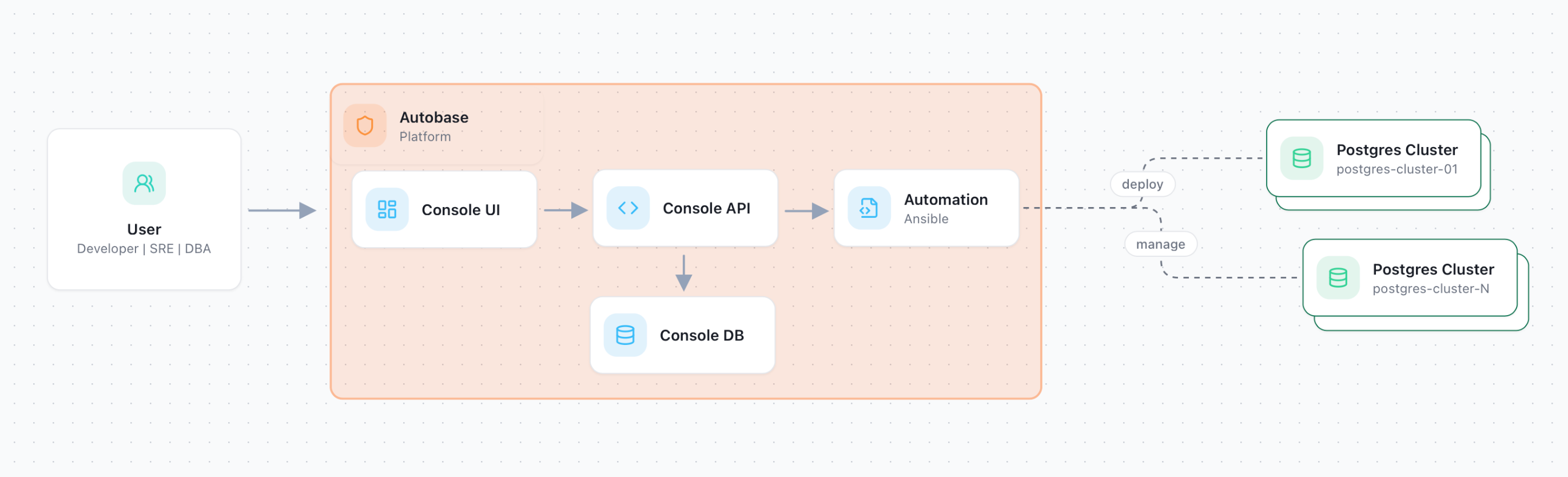
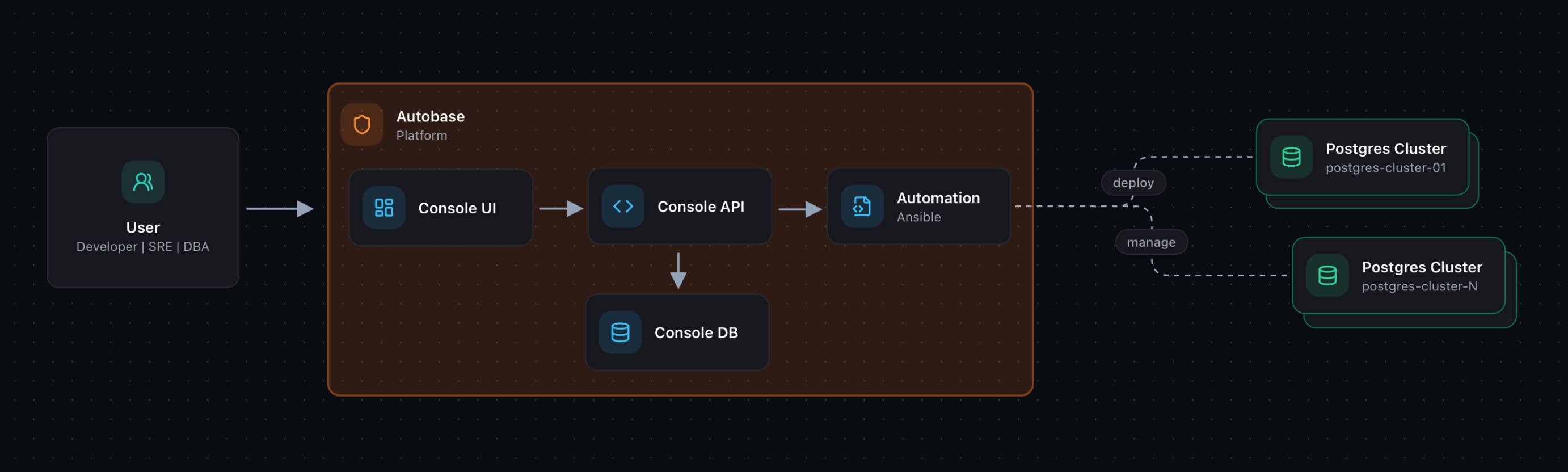
Users define cluster topology, parameters, and maintenance actions in the Console UI. The Console API validates requests, stores state in the Console DB, prepares inventory and variables, and delegates execution to the Automation container.
Autobase Automation runs Ansible playbooks to create infrastructure when needed, install and configure PostgreSQL, set up high availability, apply configuration changes, scale clusters, and perform maintenance operations. Results, logs, metadata, and status are written back to the Console DB and displayed in the UI.
Components:
- Console UI provides the web interface for creating clusters, reviewing topology, launching operations, editing configuration, and monitoring cluster status.
- Console API implements the platform backend. It handles requests from the UI, validates input, manages cluster state, interacts with the Console DB, and starts automation tasks when required.
- Console DB stores platform data, including cluster metadata, server inventory, configuration, operation history, execution results, logs, and current status.
- Automation container executes Ansible playbooks using inventories and variables prepared by the Console API. It performs deployment, configuration, scaling, maintenance, and recovery-related operations.
PostgreSQL Cluster
A highly available PostgreSQL cluster keeps the database service running when a server fails.
It consists of one Primary node that handles write traffic and one or more Replica nodes that continuously receive changes from it. If the Primary becomes unavailable, one of the Replicas can be promoted to become the new Primary.
Autobase supports three deployment schemes depending on how clients connect to the cluster:
1. High-Availability Only
This is the simplest high-availability setup. Clients connect directly to PostgreSQL nodes, while Patroni manages failover between the Primary and Replicas.
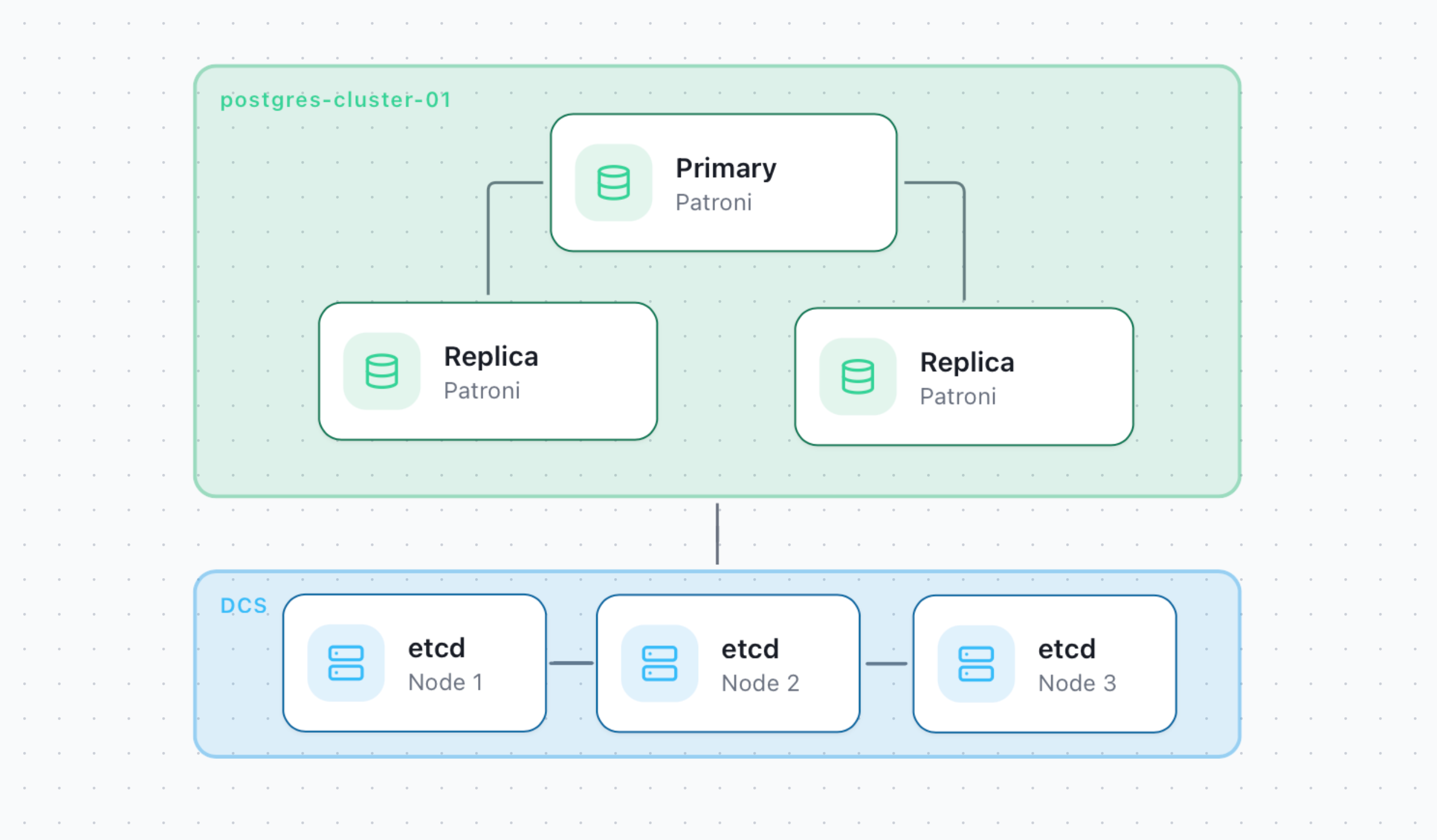
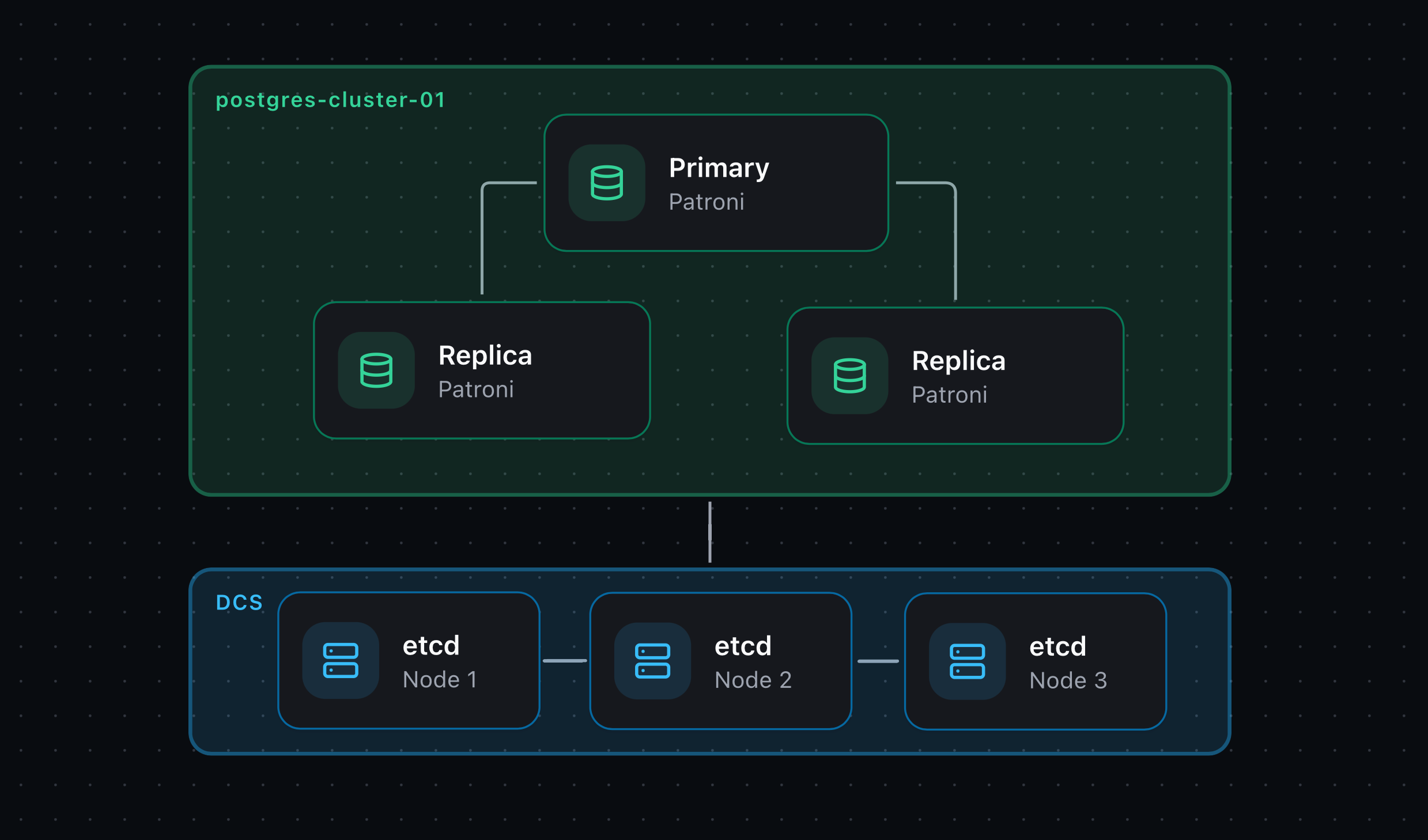
Components:
-
Patroni is a template for building customized PostgreSQL high-availability solutions using a distributed configuration store such as etcd, Consul, or ZooKeeper. Patroni runs on each PostgreSQL node, continuously monitors the local PostgreSQL instance, and coordinates cluster state through the DCS. The node that holds the leader lock acts as the primary; if it becomes unavailable, eligible replicas participate in a leader race, and the first one that acquires the leader lock promotes itself to the new primary.
-
etcd is a reliable distributed key-value store for critical data in distributed systems. etcd is written in Go and uses the Raft consensus algorithm to manage a highly available replicated log. Patroni uses etcd to store cluster state and PostgreSQL configuration parameters. What is Distributed Consensus?
Optional:
-
vip-manager runs on all cluster nodes and connects to the DCS. If the local node owns the leader key, vip-manager starts the configured VIP. During failover, vip-manager removes the VIP from the old leader, and the service on the new leader starts it there. It provides a single entry point (VIP) for database access. It is not available for cloud environments.
-
PgBouncer is a connection pooler for PostgreSQL. It is useful when applications create many short-lived connections or when the number of client connections is higher than PostgreSQL should handle directly. PgBouncer reuses server-side connections, reduces connection overhead, and helps protect PostgreSQL from connection spikes.
2. High-Availability with Load Balancing
This scheme enables load distribution for read operations and allows the cluster to scale out with read-only replicas.
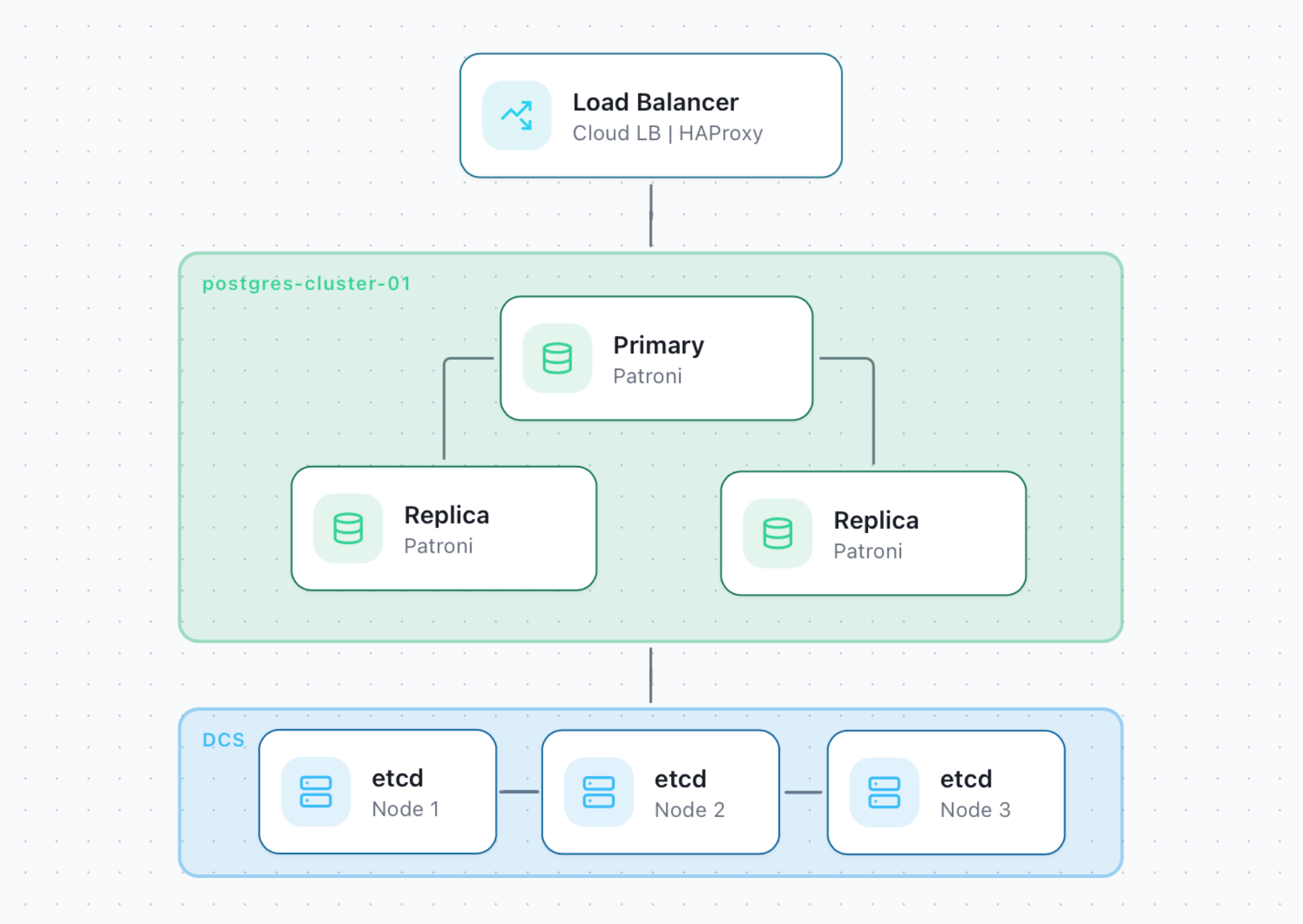
When deploying to cloud providers such as AWS, GCP, Azure, DigitalOcean, and Hetzner Cloud, a cloud load balancer is automatically created by default to provide a single entry point to the database.
For non-cloud environments, such as Your Own Machines deployments, the HAProxy load balancer is available.
List of ports when using HAProxy:
- port 5000 (read/write primary)
- port 5001 (read-only, all replicas)
- port 5002 (read-only, synchronous replica only)
- port 5003 (read-only, asynchronous replicas only)
Your application must support sending read requests to a custom address and port.
Components:
- HAProxy is a fast and reliable solution for high availability, load balancing, and proxying for TCP and HTTP-based applications.
Optional:
-
confd manages local application configuration files using templates and data from etcd or Consul. It is used to automate HAProxy configuration management.
-
Keepalived provides a highly available virtual IP address (VIP) and a single entry point for database access. It implements VRRP (Virtual Router Redundancy Protocol) for Linux. In the Autobase configuration, Keepalived checks the status of the HAProxy service and, in case of failure, moves the VIP to another server in the cluster. It is not available for cloud environments.
3. High-Availability with Consul Service Discovery
In this scheme, Consul Service Discovery with DNS resolution is used as a client access point to the database.
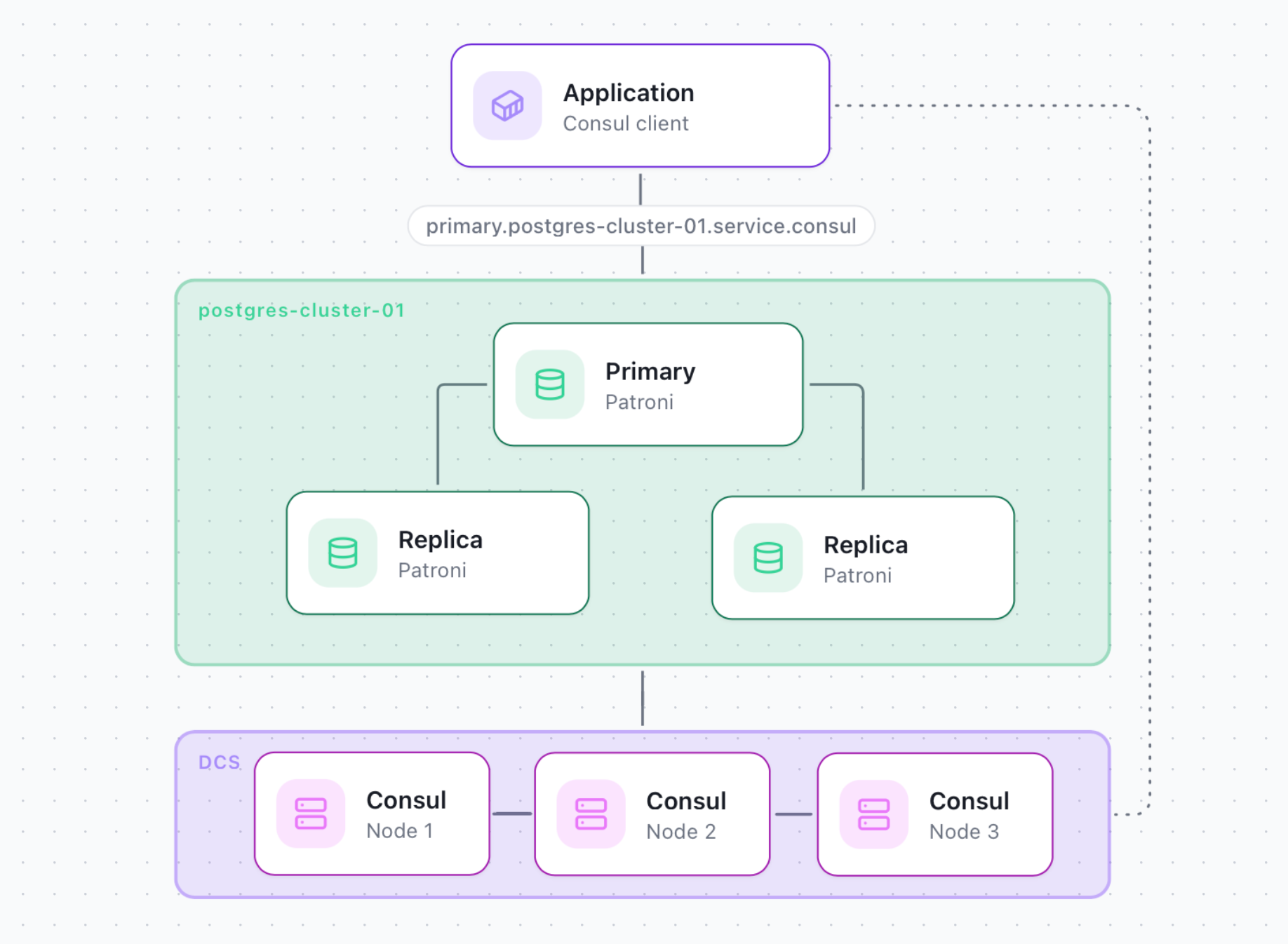
It is also suitable for primary access and read load balancing across replicas using DNS. Example:
- primary.postgres-cluster-01.service.consul
- replica.postgres-cluster-01.service.consul
This scheme can also be useful for distributed clusters across multiple data centers. You can specify the data center where each database server is located, then use that information for applications running in the same data center. Example:
- replica.postgres-cluster-01.service.dc1.consul
- replica.postgres-cluster-01.service.dc2.consul
It requires Consul in client mode on each application server for service DNS resolution. Alternatively, use DNS forwarding to a remote Consul server instead of installing a local Consul client.